

Salesforce’s CodeT5 System Can Understand and Generate Code
AI-powered coding tools, which generate code using machine learning algorithms, have attracted increasing attention over the last decade. In theory, systems like OpenAI’s Codex could reduce the time people spend writing software as well as computational and operational costs. But existing systems have major limitations, leading to undesirable results like errors.
In search of a better approach, researchers at Salesforce open-sourced a machine learning system called CodeT5, which can understand and generate code in real time. The team claims that CodeT5 achieves state-of-the-art performance on coding tasks including code defect detection, which predicts whether code is vulnerable to exploits, and clone detection, which predicts whether two code snippets have the same functionality.
Novel Design
As the Salesforce researchers explain in a blog post and paper, existing AI-powered coding tools often rely on model architectures “suboptimal” for generation and understanding tasks. They adapt conventional natural language processing pretraining techniques to source code, ignoring the structural information in programming language that’s important to comprehending the code’s semantics.
By contrast, CodeT5 incorporates code-specific knowledge, taking code and its accompanying comments to endow the model with better code understanding. As a kind of guidepost, the model draws on both the documentation and developer-assigned identifiers in codebases (e.g., “binarySearch”) that make code more understandable while preserving its semantics.
CodeT5 builds on Google’s T5 (Text-to-Text Transfer Transformer) framework, which was first detailed in a paper published in 2020. It reframes natural language processing tasks into a unified text-to-text-format, where the input and output data are always strings of text — allowing the same model to be applied to virtually any natural language processing task.
To train CodeT5, the team sourced over 8.35 million instances of code, including user-written comments from publicly available, open source GitHub repositories. Most came from the CodeSearchNet dataset — which spans Ruby, JavaScript, Go, Python, PHP, C, and C# — supplemented by two C and C# datasets from BigQuery.
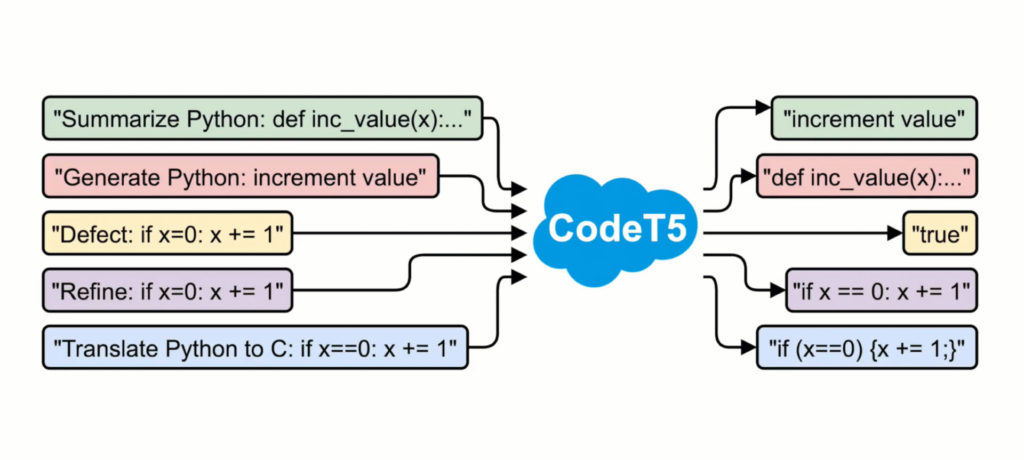
The largest and most capable version of CodeT5, which had 220 million parameters, took 12 days to train on a cluster of 16 Nvidia A100 GPUs with 40GB of memory. (Parameters are the parts of the machine learning model learned from historical training data.) The design innovations enabled it to achieve top-level performance on fourteen tasks in the CodeXGLUE benchmark, including text-to-code generation and code-to-code translation.
Potential Bias
The Salesforce researchers acknowledge that the datasets used to train CodeT5 could encode some stereotypes like race and gender from the text comments — or even from the source code. Moreover, they say, CodeT5 could contain sensitive information like personal addresses and identification numbers. And it might produce vulnerable code that negatively affects software.
OpenAI similarly found that its Codex model, which was also trained on code from open source GitHub repositories, could suggest compromised packages, invoke functions insecurely, and produce programming solutions that appear correct but don’t actually perform the intended task. Codex can also be prompted to generate racist and otherwise harmful outputs as code, like the word “terrorist” and “violent” when writing code comments with the prompt “Islam.”
But the Salesforce team says that they took steps to prune and debias CodeT5, including by cleaning and filtering the training data for problematic content. To demonstrate the model’s usefulness, the researchers built an AI-powered coding assistant for Apex, Salesforce’s proprietary programming language with Java-like syntax, that lets developers type a natural language description to generate a target function or summarize a function into code comments.
“With the goal of improving the development productivity of software with machine learning methods, software intelligence research has attracted increasing attention in both academia and industries over the last decade. Software code intelligence techniques can help developers to reduce tedious repetitive workloads, enhance the programming quality and improve the overall software development productivity,” the researchers wrote in their paper. “[Models like CodeT5] would considerably decrease their working time and also could potentially reduce the computation and operational cost, as a bug might degrade the system performance or even crash the entire system.”
CodeT5 adds to the growing list of models trained to complete software programming tasks. For example, Intel’s ControlFlag and Machine Inferred Code Similarity engine can autonomously detect errors in code and determine when two pieces of code perform similar tasks. And Facebook’s TransCoder converts code from one of three programming languages — Java, Python, or C++ — into another.
But recent studies suggest that AI has a ways to go before it can reliably generate code. In June, a team of researchers at the University of California at Berkeley, Cornell, the University of Chicago, and the University of Illinois at Urbana-Champaign released APPS, a benchmark for code generation from natural language specifications. The team tested several types of models on APPS, including OpenAI’s GPT-2, GPT-3, and an open source version of GPT-3 called GPT-Neo. In experiments, they discovered that the models could learn to generate code that solves easier problems — but not without syntax errors. Approximately 59% of GPT-3’s solutions for introductory problems had errors, while the best-performing model — GPT-Neo — attained only 10.15% accuracy.
The Salesforce researchers didn’t test CodeT5 on APPS.
Source: https://venturebeat.com/2021/09/07/salesforces-codet5-system-can-understand-and-generate-code/

